In modern natural language processing (NLP), AI models rely on several core components to process and understand human language effectively. Among these, tokens, embeddings, and attention mechanisms are fundamental. Understanding these technical building blocks is essential for AI practitioners, data scientists, and ML engineers.
1. Tokens: How Text Is Structured for AI
A token is the atomic unit of text that AI models process. Depending on the model and its tokenizer, tokens can be:
- Word-level: Each token corresponds to a word. Simple but can struggle with rare or out-of-vocabulary words.
- Subword-level (BPE, WordPiece, SentencePiece): Rare or complex words are broken into smaller, meaningful units. For instance, “transforming” might become [“trans”, “##forming”] in WordPiece tokenization.
- Character-level: Each character is a token. Provides maximum flexibility but increases sequence length and computation.
Tokenization is the first critical step in converting raw text into a form that neural networks can process efficiently. Proper tokenization ensures that models capture linguistic patterns while keeping sequence lengths manageable.
2. Embeddings: From Tokens to Vectors
After tokenization, each token is mapped to a vector embedding, which encodes semantic and syntactic information in a high-dimensional space. Key technical points include:
- Static embeddings: Pre-trained embeddings like Word2Vec or GloVe assign a fixed vector to each token, independent of context.
- Contextual embeddings: Modern transformer models like BERT, GPT, and RoBERTa generate embeddings that vary depending on surrounding tokens, capturing polysemy and context.
- Dimensionality: Typical embeddings range from 128 to 1,024 dimensions, balancing expressiveness with computational cost.
Mathematically, embeddings are often learned as part of the model’s training objective, using techniques like skip-gram, masked language modeling (MLM), or causal language modeling (CLM). These embeddings allow downstream tasks—text classification, question answering, semantic search, and summarization—to leverage rich semantic representations.
3. Attention Mechanism: Contextual Focus
The attention mechanism enables models to weigh the importance of different tokens relative to one another. In transformers, self-attention computes a weighted sum of all token embeddings in a sequence using query (Q), key (K), and value (V) matrices:
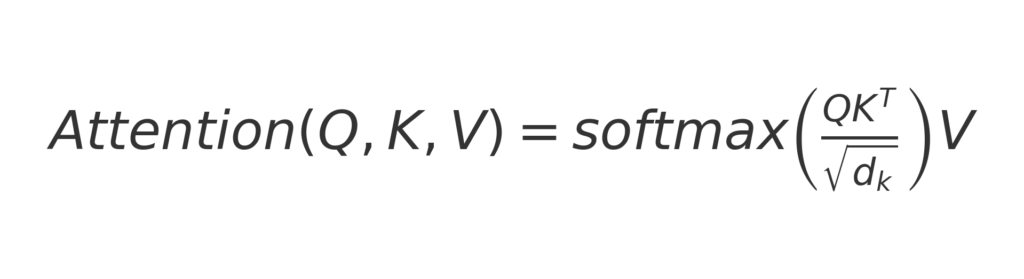
Where dk is the dimensionality of the key vectors. This allows the model to:
- Capture long-range dependencies between tokens, e.g., linking subject and predicate across a sentence.
- Dynamically adjust focus, giving more weight to contextually relevant tokens.
- Support multi-head attention, which allows the model to attend to multiple aspects of context simultaneously.
Attention mechanisms are at the core of transformer architectures, enabling state-of-the-art performance across translation, summarization, question answering, and generative AI tasks.
Why These Components Matter
- Tokenization ensures that text is efficiently processed without losing linguistic nuances.
- Embeddings convert discrete tokens into rich, high-dimensional representations that capture semantics and syntax.
- Attention allows models to dynamically focus on relevant context, enabling nuanced understanding and generation.
Ready to explore the power of AI in understanding language? Whether you’re looking to implement smarter chatbots, advanced search tools, or intelligent content analysis, understanding tokens, embeddings, and attention is the first step. Get in touch with us today to see how AI can transform the way your business processes and interprets text, unlocking new opportunities for efficiency and innovation.
